![[レポート]Apache Iceberg を使用してリアルタイムの洞察のためのオープンテーブルデータレイクを構築する #AWSreInvent](https://images.ctfassets.net/ct0aopd36mqt/3IQLlbdUkRvu7Q2LupRW2o/edff8982184ea7cc2d5efa2ddd2915f5/reinvent-2024-sessionreport-jp.jpg?w=3840&fm=webp)
[レポート]Apache Iceberg を使用してリアルタイムの洞察のためのオープンテーブルデータレイクを構築する #AWSreInvent
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
こんにちは、AWS re:Invent 2024に参加していたデータ事業本部の渡部です。
今回は4日目のWorkshopである【ANT402-R1 | Build open table data lakes for real-time insights with Apache Iceberg】のセッションレポートをまとめます。
最終日、最後に受けたセッションです!
re:Invent2024では、S3 TableやSageMaker Lakehouseなど、Iceberg関連のサービスの発表が多かったです。
そのため本セッションでIcebergをしっかり触っていきたく参加しました。
セッション概要
マンダレイベイの広い会場でワークショップが行われました。
開始前からものすごい行列で、予約をしていたことを過去の自分に感謝しました。

説明
以下はセッション説明です。
In this hands-on workshop, learn how to build a reliable and scalable streaming ingestion pipeline into Apache Iceberg–based data lakes on AWS to build a highly available, real-time data platform that can adapt to evolving data requirements. Through a series of guided exercises, learn how to use AWS streaming services to ingest data into Iceberg tables on Amazon S3 and use Amazon EMR to process the data. Implement Iceberg’s key capabilities, including atomic writes, schema evolution, and error handling for metadata management, to gracefully handle schema changes and data errors. You must bring your laptop to participate.
AI翻訳
この実践型ワークショップでは、AWS上のApache Icebergベースのデータレークに堅牢でスケーラブルなストリーミングインジェストパイプラインを構築する方法を学びます。進化するデータ要件に適応できる、高可用性の実時間データプラットフォームを構築します。一連のガイド付き演習を通じて、AWSのストリーミングサービスを使用してAmazon S3上のIcebergテーブルにデータをインジェストし、Amazon EMRを使用してデータを処理する方法を学びます。Icebergの主要機能である原子的書き込み、スキーマの進化、メタデータ管理のエラー処理を実装して、スキーマの変更やデータエラーを適切に処理します。参加するためにラップトップを持参する必要があります。
スピーカー
Abhilash Nagilla, Sr. Analytics Solutions Architect, AWS
Ekta Ahuja, Redshift Specialist Solutions Architect, AWS
セッション内容
ワークショップのアジェンダは以下の通りです。
-
ワークショップの構成について
- Apache Icebergの概要
- AWSにおけるApache Iceberg
-
このワークショップで何を学ぶか?
- ラボ01 - Amazon EMRを使用してIcebergテーブルにデータをストリーミングし、高度な機能でIcebergテーブルを管理し、Icebergの技術特徴を使用してデータを移動
- ラボ02 - AWS Glue Data CatalogとAmazon Athenaを使用したIcebergテーブルの自動メンテナンス
-
ワークショップの実施
- セットアップとセルフサービス実行の手順

まずはApache Icebergの利点について紹介がありました。
- データの一貫性 - ACIDトランザクションにより、変更は"コミット"後にのみ表示される
- 速度 - クエリプランニングにO(1)の時間複雑度;関係のないデータの迅速な除外
- 表現力のあるSQL - データレイクにSQLの機能をもたらす
- データ構造 - 柔軟なスキーマとパーティション進化
- クロスプラットフォームサポート - ベンダーロックインのない拡張可能なアーキテクチャ
- データバージョニング - タイムトラベルとロールバック機能

オープンテーブルフォーマットであることから、様々なエンジンからデータアクセスができることが説明されました。
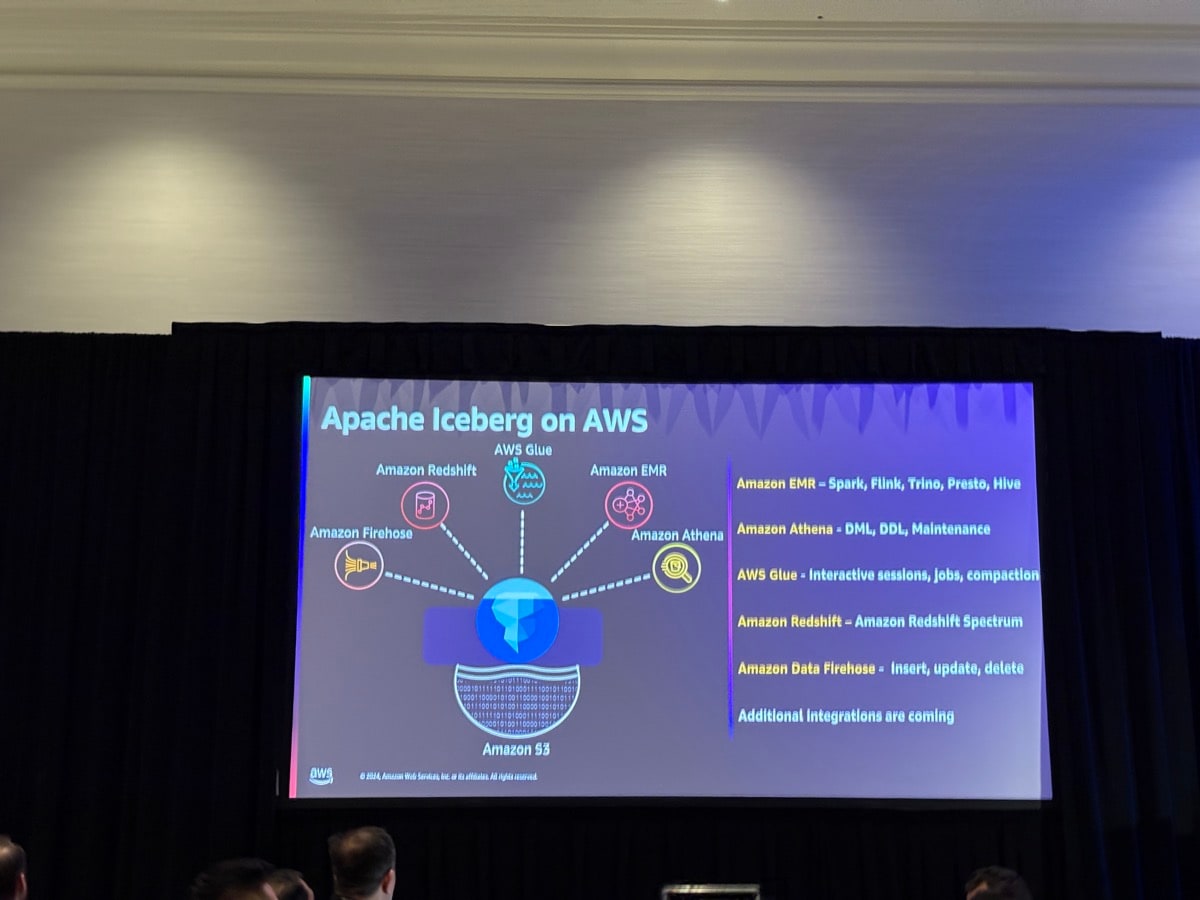
今回やるワークショップの説明です。
テーブル形式にIcebergを用いてストリーミングパイプラインを構築し、AthenaでGlue Data Catalogによる統計ありなしのパフォーマンスを見るというのが今回のワークショップとなります。
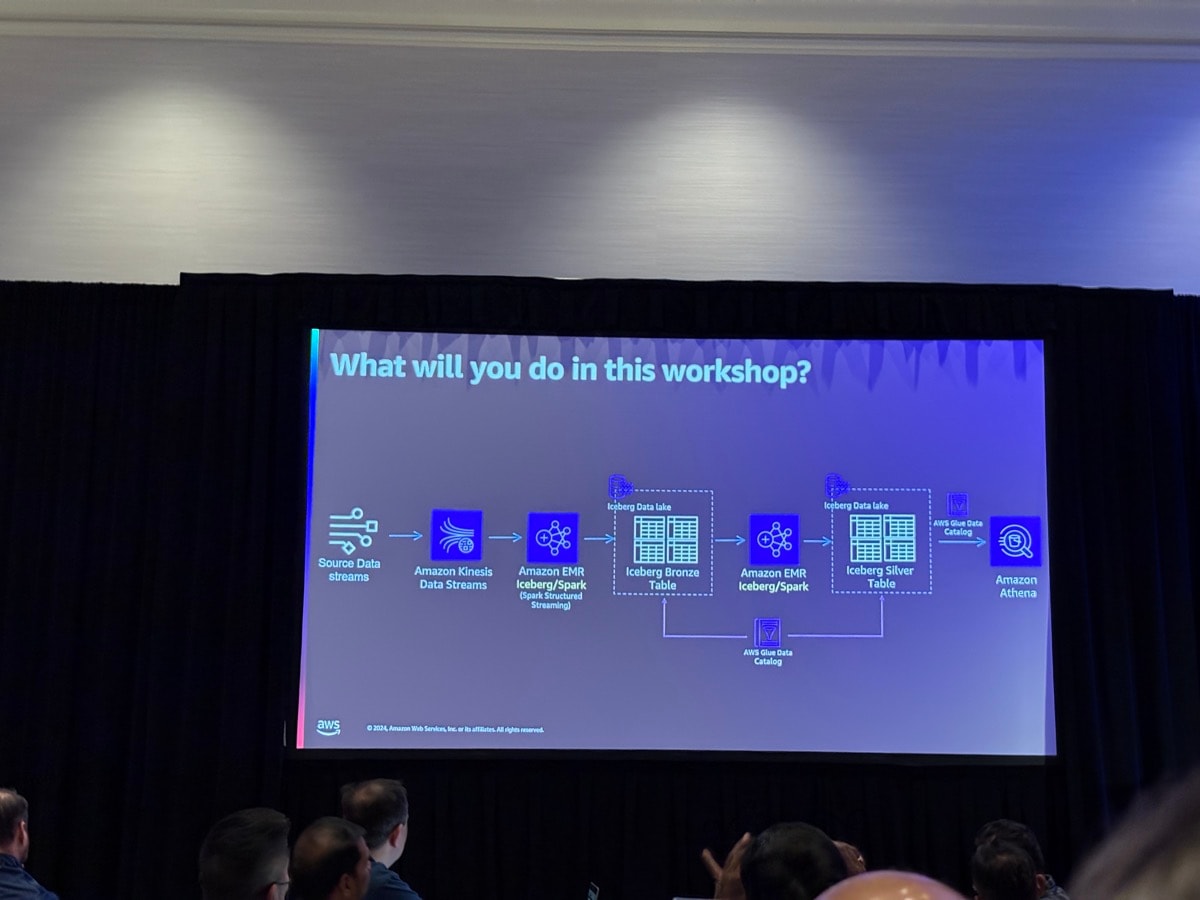
また補足程度に、今回使用するEMRのSparkはOSSのSparkよりもパフォーマンスが良いことが紹介されました。

次にIcebergの書き込みパフォーマンスについて、更新モードにおける2種類の選択肢について説明がありました。
- Copy-on-Write
- 同じパーティションに対して複数の更新がある場合に適している
- 更新時に新しいファイルを作成し、古いファイルを置き換える
- 読み取りパフォーマンスが優先される場合に有効
- Merge-on-Read
- 更新が少ない複数のパーティションがある場合に適している
- 更新をデルタファイルとして保存し、読み取り時にマージする
- 書き込みパフォーマンスが優先される場合に有効

次にAWS Glue Data Catalogの話に移り、Icebergテーブルは自動的にコンパクションされ、不要スナップショットの削除によりクエリパフォーマンスの最適化が行われるという紹介がありました。

またGlue Data Catalogによる統計計算によっても、クエリパフォーマンスは最適化されると挙げていました。

前段の説明が終わり、ここからワークショップに入っていきました。
AWSが用意した環境でドキュメントを見ながら各自で構築をしていきます。
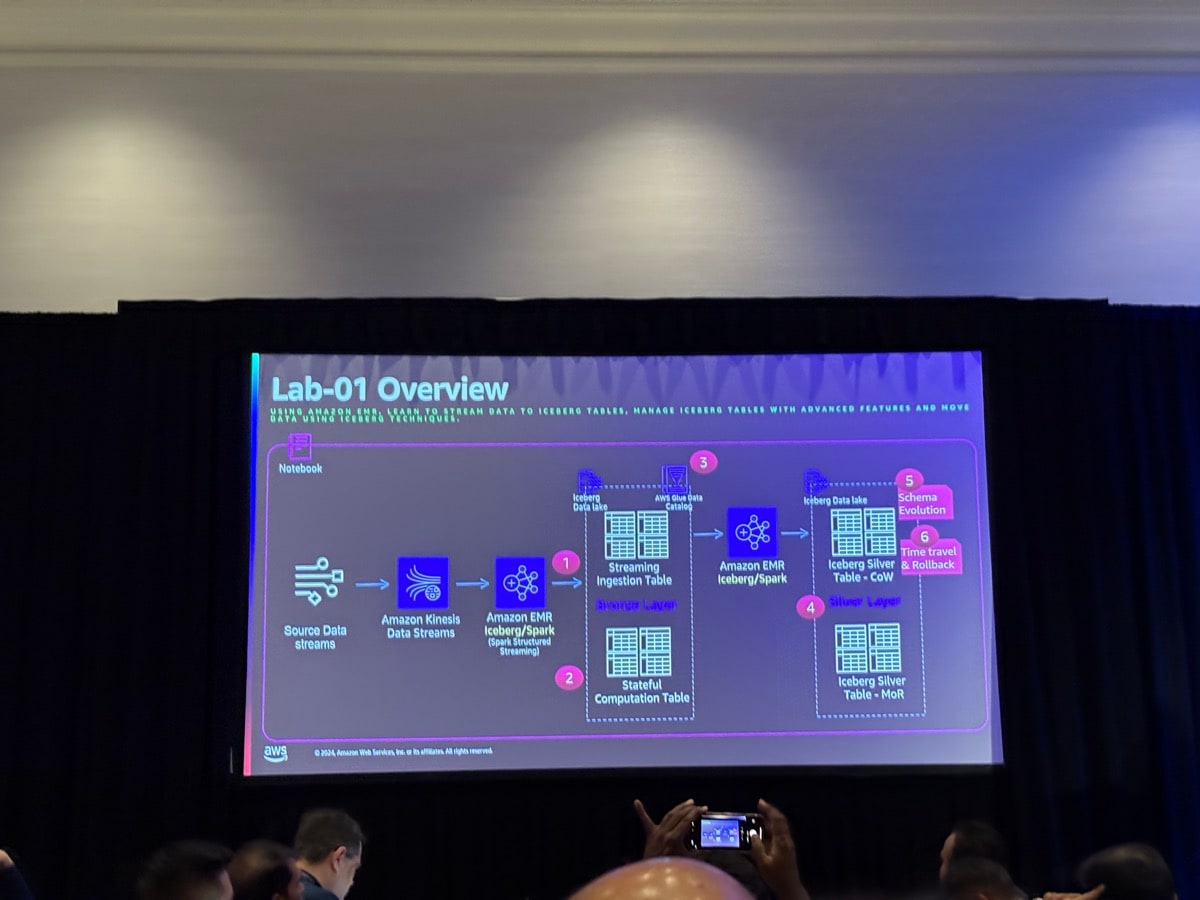
Kinesis Data StreamからのストリーミングデータをEMR Studio上でEMR ServerlessのSparkセッションを使うことで、メダリオンアーキテクチャでいうところのブロンズとシルバーをIcebergテーブルで作っていきました。
ブロンズレイヤーに関してはApache Spark Structured StreamingのappendモードでUpsertでテーブルが作られること、シルバーレイヤーに関してはデータ加工をしつつ書き込みモードをCoWとMoR両方を試してMoRのみがdelete fileが作成されることを確認しました。
具体的には以下を実行することで確認をしています。
spark.sql(f"""
SELECT * FROM {ICEBERG_DB}.{ICEBERG_SALES_TABLE_COW}.position_deletes
""").show()
その後はシルバーレイヤーのテーブルに対して、統計のありなしでのパフォーマンスを確認しました。
実際にEXPLAIN句でクエリの実行計画を見てみると、統計なしのテーブルについては以下のように?が目立ちます。
Project[projectLocality = LOCAL, protectedBarrier = NONE]
│ Layout: [s_state$gid_92:varchar, ...]
│ Estimates: {rows: ? (?), cpu: ?, memory: 0B, network: 0B}
対して統計ありのテーブルは具体的な数値が出力されています。
Project[projectLocality = LOCAL, protectedBarrier = NONE]
│ Layout: [s_state$gid_92:varchar, ...]
│ Estimates: {rows: 1447198784 (264.17GB), cpu: 264.17G, memory: 0B, network: 0B}
統計があるなしで、たとえばデータのディストリビューションがPARTITIONEDなのかREPLICATEDという点が変わります。
PARTITIONEDであれば、JOINに必要なデータを分散処理のために各ノードに分散させるのですが、大量データであればその分のネットワーク転送のオーバーヘッドがかかります。
対してREPLICATEDは全データを全ノードに複製するもので、小さいテーブルに適しているものです。大きいテーブルに適用してしまうとメモリ不足が心配されます。
統計があれば、適したディストリビューションが適用されますが、統計がない場合はメモリ不足を防ぐために、基本的にPARTITIONEDが適用されます。
特に大きいテーブル(ファクトテーブル)と小さいテーブル(ディメンションテーブル)の結合の際は、小さいテーブルをREPLICATEDにする方がネットワーク転送ロスが少なくなり、JOINのパフォーマンスは良くなります。
以上から統計は効率の良いデータ分析には重要なものであることがわかります。
また統計について、Icebergテーブルの具体的な統計算出についても触れられました。
簡単にまとめてみると、以下の順番で統計が生成され使用されていきます。
- データが書き込まれる
- AWS Glue Data Catalogが統計情報の生成をトリガー
- Theta Sketchアルゴリズムでデータをサンプリング
- 統計情報をapache-datasketches-theta-v1形式でPuffinファイルに保存
- クエリ実行時にこの情報を使用して最適化
調べてみると、Theta Sketchは大規模データから一意な値の数(NDV)を推定するアルゴリズムのことで、Puffinファイルにはそこから得た統計情報を保存します。
統計情報の一つ、NDVを把握することでどんなことが嬉しいのか?というと、先述したディストリビューションの適用に一役買うというわけです。
なかなかに理解が難しいですが、少しずつ調べていくとよくこんな仕組みを作ったなあとしみじみ思いつつ、それぞれの要素が絡み合っていて面白いなと感じます。
さいごに
ワークショップを受ける前はIcebergについてはなんとなく知っている程度だったのですが、このワークショップを受けることでわからないことが明確になり、そのおかげで理解が深めることができました。
re:Invent2024ではLakehouseやS3 TableなどIcebergに関するアップデートが多かったです。今後Icebergはより多くの場面で活用されていくのは確実なので、キャッチアップをこれからも続けていこうと思います。
以上です。どなたかのご参考になれば幸いです。










